NYC Capital Projects¶
This project is an exploratory analysis experimenting with different approaches to modeling and feature engineering to predict budget and schedule outcomes for New York City-managed capital projects with budgets greater than $25 million, using a `data set hosted by NYC Open Data <datasource_>`_.
Contents
Summary¶
This analysis is built upon one initially completed as a group project for `CS109B: Advanced Topics In Data Science`_, a course offered by Harvard University’s John A. Paulson School of Engineering and Applied Sciences (SEAS). The authors of that original project are:
The original version of this project can be found by viewing release version v1.0.0 on GitHub at: https://github.com/sedelmeyer/nyc-capital-projects/tree/v1.0.0.
Alternatively, the most up-to-date (i.e. latest released) version of this project can be found at: https://github.com/sedelmeyer/nyc-capital-projects.
The final report summarizing the methods and findings for this project can be found in `the Jupyter notebook-based report for that project <final report_>`_.
Research question¶
After initial exploration and cleansing of the available data, modeling efforts in this analysis focus on the following research question:
Given `the available New York City Capital Projects change data <datasource_>`_, can we create a model that can accurately predict 3-year change in forecasted project budget and 3-year change in forecasted project duration using only the data available at the start of the project as our predictors?
In other words, using historical project data, can we predict how much the forecasted budget and duration of any given capital project run by the City of New York will deviate from it’s original budgeted estimates by the end of year-3 for the project?
The significance of a model that can accurately address this question means, given any new project, project managers and city administrators would have another tool at their disposal for objectively identifying potential budget and schedule risk at the start of a new city-run capital project. Such a tool can help to overcome common planning fallacies and optimism biases to help to mitigate cost and and schedule overruns.
Analysis and outcomes¶
Documentation for this project’s anlysis and findings can be found here:
https://sedelmeyer.github.io/nyc-capital-projects/analysis.html
NOTE: The next release of this project will include an html version of the in-depth project findings illustrated in `the final report notebook <final report_>`_.
Source code API documentation¶
Documentation for the python modules built specifically for this analysis (i.e. modules located in this project’s caproj package) can be found here:
https://sedelmeyer.github.io/nyc-capital-projects/modules.html
Replicating this analysis¶
In order to replicate this analysis and run the Python code available in this analysis locally, follow these steps:
In this section
0. Ensure system requirements are met¶
In order to successfully run this project locally, your system will need the following dependencies:
Python version
>=3.6Pipenv for dependency management and packaging.
Documentation on how to install Pipenv can be found here: https://pipenv.pypa.io/en/latest/install/#installing-pipenv.
If you prefer to use Conda or some other tool for dependency management and packaging, you can do so using the
requirements.txtfile located in this repository.However, please note that it may take some work to get your project configured to run properly using those other tools.
Graphviz for generating the directed graphs located in several notebooks.
The latest version of Graphviz can be downloaded from here: https://graphviz.org/.
1. Clone this repository locally¶
This project can by cloned locally using the command:
git clone https://github.com/sedelmeyer/nyc-capital-projects.git
Alternatively, you can download a ZIP of the entire repository from here: https://github.com/sedelmeyer/nyc-capital-projects/archive/master.zip
2. Install the required environment using Pipenv¶
If you are new to using Pipenv for managing your working environments, please take some time to familiarize yourself with the tool. The official Pipenv documentation is a good place to start.
To install your Python dependencies directly from the deterministic build specified by the Pipfile.lock, simply run:
pipenv install --dev
Once your pipenv environment is built, you can enter it with:
pipenv shell
From within your pipenv shell, to start up a Jupyter notebook server with access to that environment, run:
jupyter notebook
To exit your pipenv shell, from within that shell, simply run:
exit
If you prefer to use a different tool for installing your dependencies and managing your working environment (such as conda, virtualenv, poetry, etc.), a requirements.txt file is provided with this project to make it easier for you to ensure matching dependency versions.
To use one of those other tools in place of Pipenv, you will likely need to do some minor reconfiguration of the project repository for everything to run smoothly.
3. Explore the associated source code and Jupyter notebooks included with this project¶
Custom source modules for this project can be found in the caproj package located in this project’s src/caproj/ directory. The API reference documentation for the caproj package can be found in the online documentation at: https://sedelmeyer.github.io/nyc-capital-projects/modules.html
This project’s analysis was performed entirely within Jupyter notebooks, all of which are located in the notebooks/ directory.
In order to reproduce the findings of this analysis, the notebooks for this project need to be run in sequential order (outputs from some notebooks are required as inputs for others). For that reason, each notebook is numbered.
The final detailed analysis for this project (i.e. final report) is provided in the last of these notebooks, notebooks/11_FINAL_REPORT.ipynb.
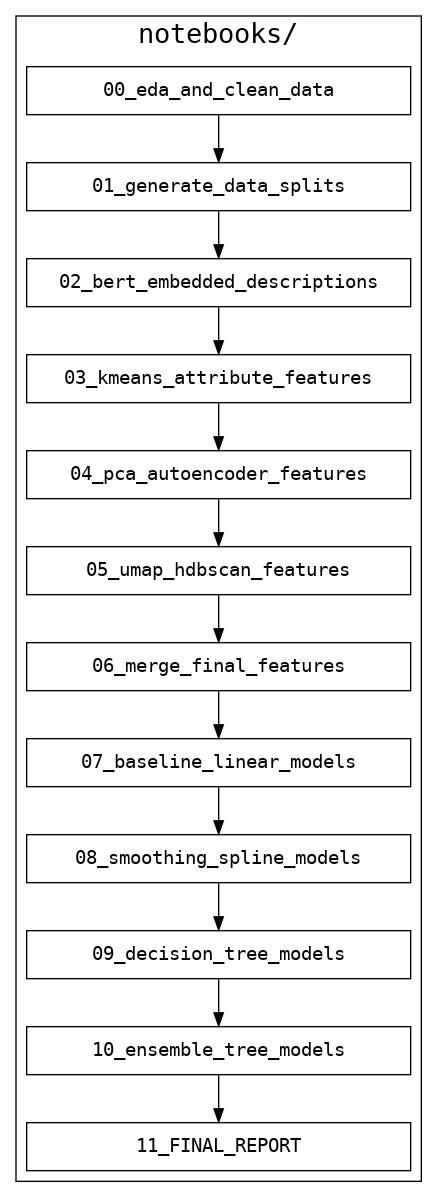
The Jupyter notebook workflow for this project.¶
Adding to this project¶
If you’d like to fork or clone this project to build off of it to explore additional methods or to practice your own data science and development skills, below are some important notes regarding the configuration of this project.
In this section
Project repository directory structure, design, and usage¶
The repository structure, packaging, and workflows for this project are largely based on the conventions used in the cc-pydata Cookiecutter template available here. Besides the additional notes provided below, the online tutorial for that template will be a useful resource for better understanding the configuration of this project and its associated components.
Python package configuration¶
Custom source modules associated with this project are accessed via the included caproj package. This package is configured via the setup.py and setup.cfg files found in this repository. The source code for this package is located in the src/caproj/ directory. For general information on the benefits to this approach for packaging a Python library, please see this article.
Testing¶
This project is configured for automated testing using tox and continuous integration services via GitHub Actions. Additionally, the pytest test-runner is used for running the associated (albeit minimal) test suite located in the tests/ directory.
If you are new to
tox, please see the official Tox documentation.If you are new to GitHub Actions, additional information can be found here.
If you are new to
pytest, please see the official pytest documentation.
Project versioning¶
This project is configured to use setuptools_scm to manage and track the project’s current release version. By using setuptools_scm, the caproj package’s setup.py pulls the version number directly from the latest git tag associated with the project. Therefore, instead of manually setting a global __version__ variable in the application, you simply add a tag when commiting a new version of this project to the master branch.
If you are new to
setuptools_scm, please see the official documentation.
Documentation using Sphinx and reStructuredText¶
Documentation for this project is written using reStructuredText markup and the resulting html documentation is generated using Sphinx.
If you are new to Sphinx, please see the Sphinx documentation.
If you are new to reStructureText, a good starting place will be the reStructuredText documentation provided by the Sphinx project.
